The best open-source Neo4j alternatives in 2026 are ArcadeDB, Memgraph, FalkorDB, ArangoDB, HugeGraph, and LadybugDB. Below we compare each graph database on licensing, performance benchmarks, multi-model support, and AI readiness — with honest pros and cons for every option.
If you’re searching for a Neo4j alternative — or a full Neo4j replacement — you’ve probably noticed a pattern: every graph database comparison article is written by a vendor, and — surprise — that vendor always comes out on top.
We’re not going to pretend we’re different. This article is published on the ArcadeDB blog, and yes, we think ArcadeDB is the best graph database in 2026 for most use cases. But here’s what we will do differently: we’ll only compare databases that are actually available in 2026, we’ll be transparent about licensing (because “open-source” doesn’t mean what some vendors want you to think it means), and we’ll acknowledge where each product genuinely shines.
No defunct products. No proprietary databases pretending to be open-source. Just a fair graph database comparison of what’s actually out there.
What Makes a Real Neo4j Alternative?
Before diving in, let’s define the criteria. A credible Neo4j alternative in 2026 should be:
- Actively maintained — regular releases, responsive community, not abandoned or in corporate limbo
- Genuinely open-source or source-available — with an honest description of what the license actually allows
- Graph-native — not a relational database with a graph extension bolted on
- Production-ready — ACID transactions, persistence, security, and scalability
- Standards-compatible — supporting established query languages (SQL, Cypher, Gremlin, or GraphQL)
We’ll also evaluate each database on multi-model capabilities, AI/agent readiness (MCP, vector search, embeddings), and total cost of ownership — because the sticker price is only part of the story.
1. ArcadeDB
License: Apache 2.0 (fully open-source, no restrictions, no data caps, forever)
Query Languages: SQL, Cypher, Gremlin, GraphQL, MQL (MongoDB-compatible)
Data Models: Graph, Document, Key-Value, Time-Series, Vector, Search
Written in: Java
Persistence: Disk-based with in-memory caching
Why It Stands Out
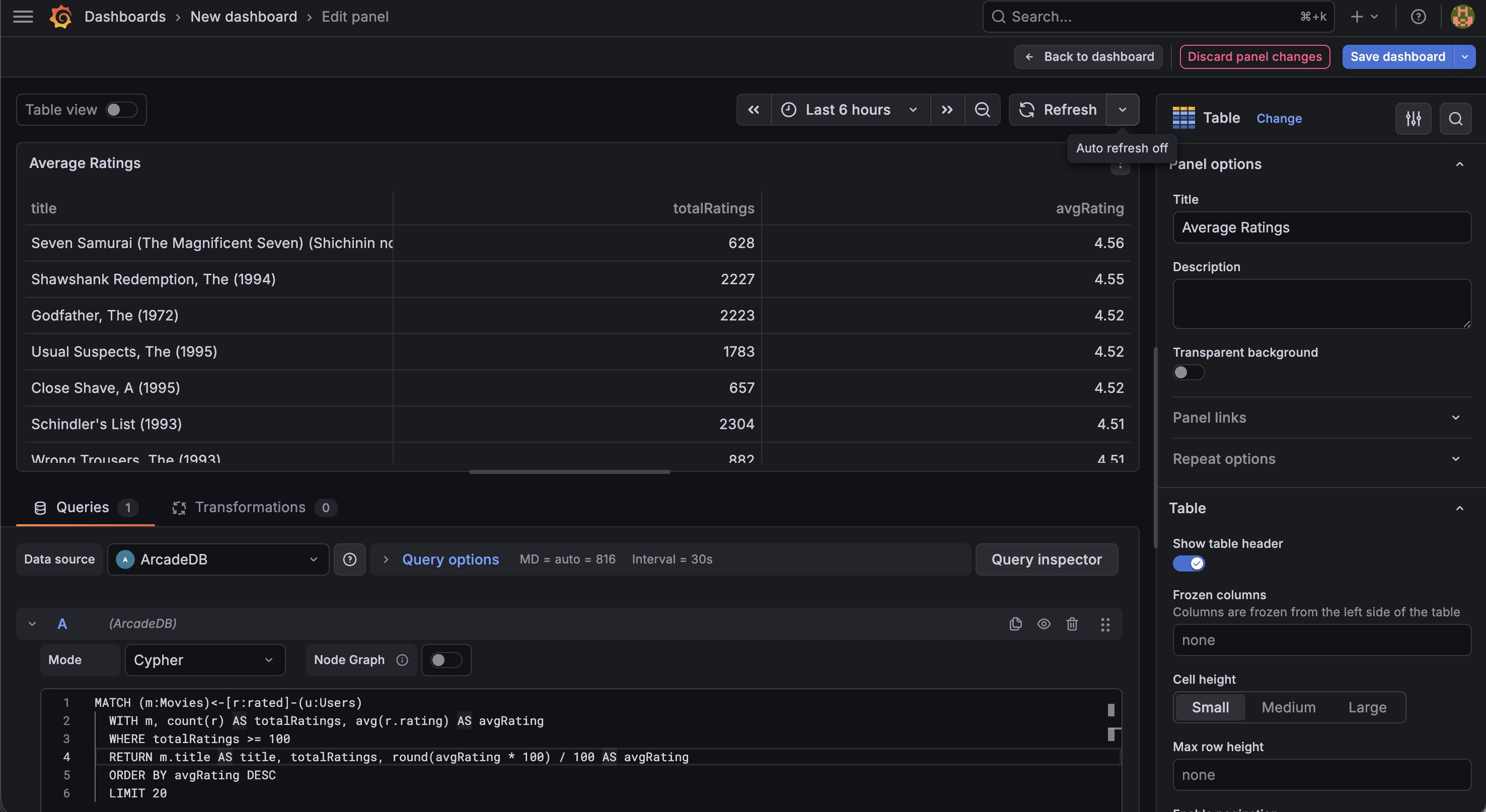
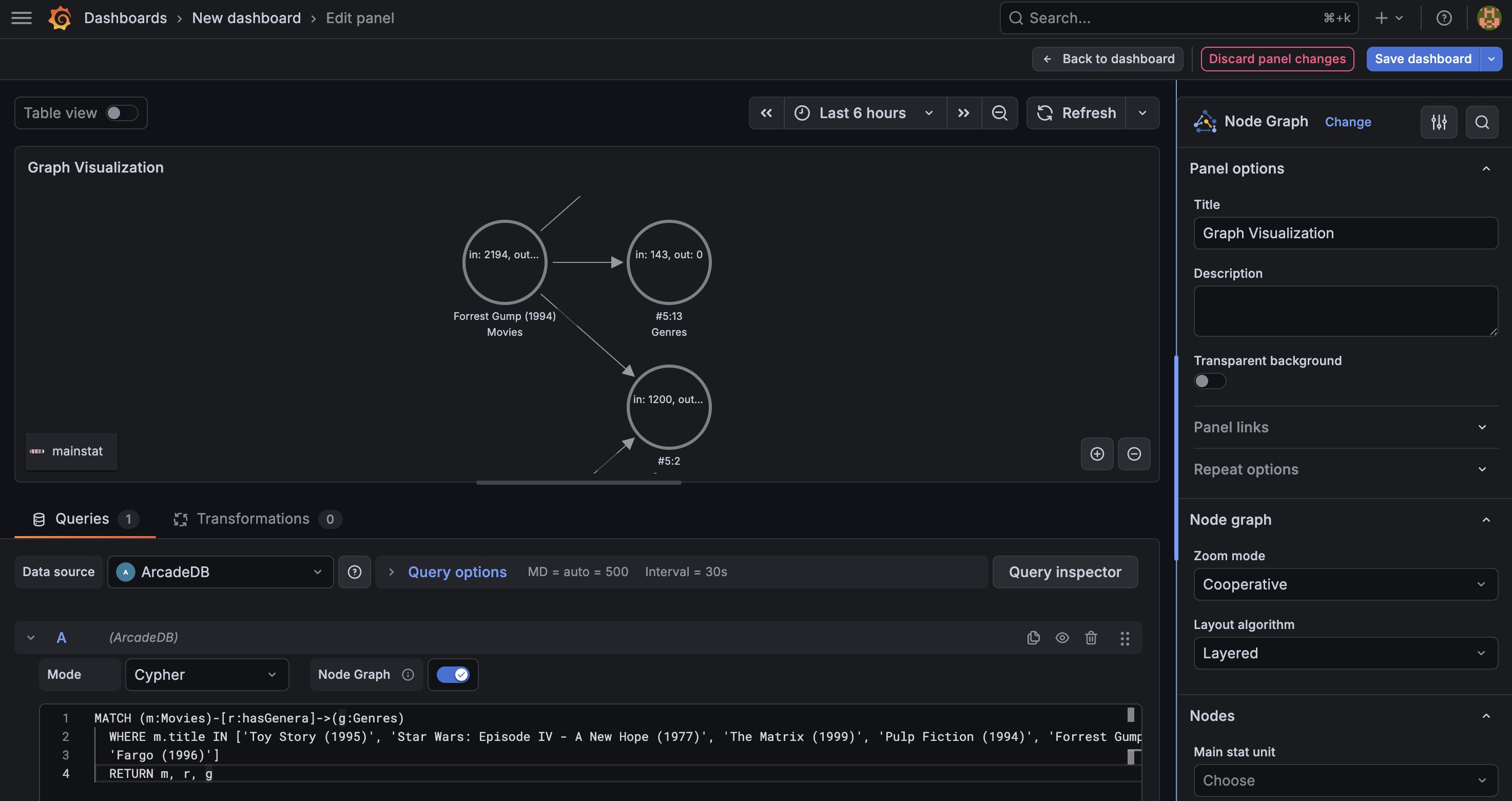
ArcadeDB is the only graph database that supports SQL, Cypher, Gremlin, GraphQL, and MongoDB query API under a single Apache 2.0 license. With five query languages and six data models in one engine, you can query the same data as a graph with Cypher, as documents with SQL, and through a MongoDB-compatible API — all without data duplication or ETL pipelines.
Licensing clarity. ArcadeDB uses Apache 2.0 — the most permissive license in the open-source world. No BSL, no SSPL, no “community edition” with artificial caps. You can use it commercially, embed it, modify it, and distribute it without paying a cent or asking permission. We’ve publicly committed to never changing this license.
AI and agent readiness. ArcadeDB ships with a built-in MCP server that lets LLMs and AI agents query your database directly using the Model Context Protocol. It also supports vector search natively — no plugins, no separate infrastructure.
Performance. ArcadeDB can ingest over 2 million records per second on commodity hardware and handle complex multi-hop graph traversals efficiently thanks to its native graph engine. With the new Graph OLAP Engine, ArcadeDB leads on every algorithm in the LDBC Graphalytics benchmark — both in embedded mode (in-process Java) and as a Docker container (same conditions as Neo4j, Memgraph, FalkorDB, and HugeGraph):
| Algorithm |
ArcadeDB |
ArcadeDB Docker |
Neo4j 2026 |
Kuzu |
DuckPGQ |
Memgraph |
ArangoDB |
FalkorDB |
HugeGraph |
| PageRank |
0.48s |
0.83s |
11.15s |
4.30s |
6.14s |
16.90s |
157.01s |
1.67s |
4.01s |
| WCC |
0.30s |
0.22s |
0.75s |
0.43s |
13.93s |
crash |
78.03s |
0.85s |
6.71s |
| BFS |
0.13s |
0.07s |
1.91s |
0.86s |
2,754s |
11.72s |
511.55s |
0.20s |
0.54s |
| LCC |
27.41s |
34.98s |
45.78s |
N/A |
38.59s |
N/A |
N/A |
N/A |
272.04s |
| SSSP |
3.53s |
0.97s |
N/A |
N/A |
N/A |
N/A |
301.93s |
N/A |
N/A |
| CDLP |
3.67s |
3.35s |
6.43s |
N/A |
N/A |
N/A |
407.41s |
5.38s |
62.70s |
Even running as a Docker container — with network serialization overhead, HTTP API, and Docker Desktop’s VM layer — ArcadeDB is still the fastest on every algorithm. The Docker results are measured warm (JIT-compiled), matching how production servers run. Results are fully reproducible — see the benchmark project on GitHub.
Neo4j vs ArcadeDB
The core difference comes down to philosophy: Neo4j is a graph-only database with proprietary enterprise features, while ArcadeDB is a multi-model engine that treats graph as one of six natively supported data models. For teams evaluating a Neo4j migration, ArcadeDB offers the smoothest path — your Cypher queries work as-is (97.8% TCK compliance), the BOLT protocol is supported, and there’s a built-in Neo4j importer. You gain multi-model capabilities without giving up graph performance.
Where It’s Not the Best Fit
- Pure in-memory streaming workloads — if your use case is 100% real-time stream processing with no persistence needs, an in-memory engine like Memgraph may have lower latency for that specific pattern.
- Cypher-only teams — while ArcadeDB supports Cypher (via the OpenCypher standard), teams deeply invested in Neo4j’s APOC library or GDS plugin will need to adapt some procedures.
- Embedded analytics — if you need an embeddable, in-process analytical engine (like DuckDB but for graphs), KuzuDB’s architecture was purpose-built for that niche.
2. ArangoDB
License: BSL 1.1 (Community Edition); Proprietary (Enterprise Edition)
Query Language: AQL (ArangoDB Query Language) — proprietary
Data Models: Graph, Document, Key-Value
Written in: C++
Persistence: Disk-based (RocksDB)
The Good
ArangoDB was one of the first multi-model databases, and it does document + graph + key-value well. The SmartGraphs feature (Enterprise only) enables efficient distributed graph traversals, and the Foxx microservices framework lets you run JavaScript inside the database.
The Problems
The license changed. ArangoDB moved from Apache 2.0 to Business Source License (BSL 1.1) starting with version 3.12 in 2024, limiting its Community Edition to 100GB. The Community Edition now has a 100GB dataset size limit and restricts commercial redistribution. If your data grows beyond 100GB, you either pay for Enterprise or you’re stuck. This is exactly the kind of bait-and-switch that erodes trust — years of community contributions under Apache 2.0, now locked behind a commercial license.
Proprietary query language. AQL is ArangoDB’s own language. It doesn’t follow SQL, Cypher, Gremlin, or any established standard. This creates vendor lock-in: your queries, your team’s knowledge, and your application logic are all tied to a language that only one database speaks. If you ever need to migrate, you’re rewriting everything.
No standard graph query support. ArangoDB doesn’t support Cypher, Gremlin, or GraphQL. For teams coming from Neo4j, this means a complete rewrite of all graph queries into AQL — which defeats the purpose of seeking a “Neo4j alternative.”
The company rebranded to arango.ai — signaling a pivot toward AI/ML positioning, though the core database technology hasn’t fundamentally changed.
| Feature |
ArcadeDB |
ArangoDB Community |
| License |
Apache 2.0 |
BSL 1.1 |
| Data size limit |
None |
100GB |
| Cypher support |
Yes |
No |
| SQL support |
Yes |
No |
| Gremlin support |
Yes |
No |
| Vector search |
Built-in |
Plugin (Enterprise) |
| MCP server |
Built-in |
No |
3. KuzuDB / LadybugDB
License: MIT (KuzuDB, archived); MIT (LadybugDB, community fork)
Query Language: Cypher
Data Model: Graph (property graph)
Written in: C++
Persistence: Disk-based, columnar
What Happened
KuzuDB was a promising embedded graph database — think “DuckDB for graphs.” It was MIT-licensed, blazing fast for analytical queries, and backed by solid academic research from the University of Waterloo. KuzuDB was archived on GitHub in October 2025 following its acquisition by Apple. Active development stopped.
The community responded with forks, the most notable being LadybugDB. But community forks of abandoned projects face harsh realities: no funding, no core team continuity, and an uncertain roadmap.
Strengths (When It Was Active)
- Excellent OLAP performance for analytical graph queries
- Embeddable (in-process, no server required)
- Clean Cypher implementation
- MIT license (the fork preserves this)
Limitations
OLAP only. KuzuDB was designed for analytical workloads — batch processing, multi-hop aggregations, graph analytics. It was never built for OLTP transactional workloads: concurrent writes, real-time updates, or serving live application traffic. If your use case involves any of those, KuzuDB was never the right tool.
Abandoned. The original project is archived. LadybugDB and other forks are community efforts without corporate backing, commercial support, or guaranteed longevity. Building production infrastructure on an abandoned project fork is a risk most teams can’t justify.
No multi-model support. Graph only. No documents, no key-value, no vector search, no time-series. If your data doesn’t fit neatly into a property graph, you need a second database.
No server mode. KuzuDB was embedded — great for single-user analytics, problematic for multi-user applications, microservices, or any architecture that needs a shared database server.
If you’re currently on KuzuDB and looking to migrate, we wrote a detailed migration guide.
4. Memgraph
License: BSL 1.1 (source-available, NOT open-source by OSI definition)
Query Language: Cypher
Data Model: Graph (property graph)
Written in: C++
Persistence: In-memory with optional snapshots (WAL)
The Good
Memgraph is genuinely fast for real-time graph workloads. Its in-memory architecture and C++ implementation deliver low-latency query execution, and the Cypher + Bolt protocol compatibility makes it a relatively smooth migration path from Neo4j. The MAGE library provides useful graph algorithms, and the streaming integrations (Kafka, Pulsar) are well-implemented.
NASA’s switch from Neo4j to Memgraph is a legitimate validation of its capabilities for specific high-performance use cases.
The Problems
It’s not open-source. Despite marketing itself as “open-source” on its website, GitHub README, and pricing pages, Memgraph uses the Business Source License 1.1. The BSL explicitly restricts commercial use — you cannot offer Memgraph as a service or build competing products. The Open Source Initiative does not recognize BSL as open-source. When a vendor calls BSL “open-source,” they’re either confused about licensing or deliberately misleading users. Independent analysis confirms neither the Community nor Enterprise edition qualifies as FOSS.
Expensive commercial licensing. Memgraph’s commercial pricing starts at approximately $25,000/year for 16GB of RAM. For comparison, you can run ArcadeDB on a 128GB server with terabytes of persistent storage for the cost of the hardware alone — because the software is free.
In-memory means in-expensive. An in-memory database requires all your data to fit in RAM. RAM is 30-50x more expensive per GB than SSD storage. For a 500GB dataset, you’re looking at server costs that dwarf any software license. Memgraph offers WAL and snapshots for durability, but recovery after a crash means reloading the entire dataset into memory — which can take significant time for large graphs.
Stability issues. Memgraph suffers from serious stability problems — the WCC benchmark crashed the server every time we ran it. Investigating further, we found 47 open issues on their GitHub reporting random crashes triggered even by simple queries, some of which have remained unaddressed for over 3 years.
Self-published benchmarks. Memgraph claims to be a faster alternative to Neo4j, but the LDBC Graphalytics benchmark tells a different story: not only is it significantly slower than Neo4j across the board, but Memgraph’s own claim of being “8x faster than Neo4j in reads and 50x faster in writes” is based on self-published benchmarks. Due to BSL restrictions, competing vendors cannot reproduce or independently verify them. Take vendor benchmarks — including ours — with appropriate skepticism.
Graph only. No document model, no key-value, no vector search, no time-series. If you need anything beyond a property graph, you need additional infrastructure.
| Feature |
ArcadeDB |
Memgraph |
| License |
Apache 2.0 |
BSL 1.1 |
| OSI-approved open-source |
Yes |
No |
| Persistence |
Native disk-based |
In-memory (snapshots) |
| Storage cost (500GB data) |
~$50/mo (SSD) |
~$2,500/mo (RAM) |
| Multi-model |
6 data models |
Graph only |
| Query languages |
5 (SQL, Cypher, Gremlin, GraphQL, MQL) |
1 (Cypher) |
| Vector search |
Built-in |
No |
| MCP server |
Built-in |
No |
| Commercial license cost |
$0 |
~$25,000/year |
5. FalkorDB
License: Source-available (Server Side Public License / Redis-style)
Query Language: Cypher (OpenCypher with extensions)
Data Model: Graph (property graph)
Written in: C (with GraphBLAS)
Persistence: Disk-based (Redis-compatible)
The Good
FalkorDB has a genuinely unique architecture: it uses GraphBLAS — sparse matrix algebra with hardware-accelerated SIMD instructions — to execute graph operations. This is an innovative approach that delivers strong performance for specific query patterns, particularly subgraph matching and pattern recognition.
FalkorDB is also positioning aggressively for AI use cases with its GraphRAG SDK, which can automatically generate graph ontologies from unstructured data — a compelling feature for teams building knowledge graphs from documents.
The project emerged as a fork of RedisGraph after Redis Inc. discontinued it in 2023, and the team has done solid work extending it into a standalone product.
Limitations
Redis heritage. FalkorDB’s architecture still carries Redis DNA — the single-threaded execution model, the Redis serialization protocol, and the in-memory-first design philosophy. While the team has added persistence and is working on multi-threading, the architectural foundations have implications for write-heavy concurrent workloads.
Source-available, not open-source. Like Memgraph, FalkorDB uses a source-available license (SSPL-adjacent) that restricts how you can deploy and distribute the software commercially. It’s more permissive than BSL for self-hosted use, but it’s not Apache 2.0 or MIT.
Graph only (with vector search). FalkorDB added HNSW-based vector indexing in v4.0, supporting cosine and Euclidean similarity search on embeddings. However, it remains graph-only for other data models — no document storage, key-value, or time-series support without separate infrastructure.
Limited graph algorithm coverage. FalkorDB (a RedisGraph fork) has no built-in LCC or full SSSP algorithm. Its algo.SSpaths is pair-oriented, not a full single-source Dijkstra — which limits its usefulness for classic graph analytics workloads.
Ecosystem maturity. FalkorDB is relatively young as a standalone product (forked in 2023). The tooling, documentation, and third-party ecosystem are still developing. Enterprise features like fine-grained access control and audit logging are less mature than longer-established alternatives.
6. HugeGraph
License: Apache 2.0
Query Language: Gremlin, RESTful API
Data Model: Graph (property graph)
Written in: Java (server), Go (Vermeer OLAP engine)
Persistence: Disk-based (pluggable backends: RocksDB, HBase, Cassandra, etc.)
The Good
HugeGraph is an Apache Software Foundation top-level project, which gives it genuine open-source governance — not a single-vendor project that can change its license overnight. It supports pluggable storage backends (RocksDB, HBase, Cassandra, MySQL, ScyllaDB) and can scale horizontally for very large graphs.
The Vermeer OLAP engine is a separate Go-based compute engine designed for graph analytics at scale. It loads data into memory and runs algorithms like PageRank, WCC, BFS, LCC, and Label Propagation (CDLP) via a REST API. This separation of OLTP (HugeGraph Server) and OLAP (Vermeer) is architecturally clean.
HugeGraph also benefits from strong adoption in China, particularly at Baidu (where it originated) and other major tech companies.
The Problems
Performance lags behind. In our LDBC Graphalytics benchmark, HugeGraph/Vermeer is significantly slower than ArcadeDB on every algorithm. Even comparing Docker-to-Docker (apples-to-apples): PageRank 4.8x slower, WCC 30x slower, BFS 7.7x slower, LCC 7.8x slower, and CDLP 18.7x slower. The LCC result (272s vs ArcadeDB Docker’s 35s) and CDLP (63s vs 3.4s) are particularly weak.
No weighted SSSP. Vermeer’s built-in SSSP algorithm only computes unweighted shortest paths (hop count). There is no weighted Dijkstra variant, which limits its usefulness for real-world graph analytics where edge weights represent distances, costs, or latencies.
No Cypher support. HugeGraph uses Gremlin and its own REST API — no Cypher, no SQL, no GraphQL. For teams migrating from Neo4j, this means a complete query rewrite. Gremlin is a recognized standard (Apache TinkerPop), but it’s verbose compared to Cypher for pattern matching queries.
Complex deployment. Running HugeGraph requires multiple components: HugeGraph Server for OLTP, Vermeer master + worker containers for OLAP, and a storage backend. The setup is significantly more complex than single-binary alternatives like ArcadeDB.
Documentation and ecosystem. Much of HugeGraph’s documentation and community discussion is in Chinese. English documentation exists but is less comprehensive. The third-party ecosystem (drivers, integrations, tutorials) is smaller than Neo4j, ArcadeDB, or Memgraph.
| Feature |
ArcadeDB |
HugeGraph |
| License |
Apache 2.0 |
Apache 2.0 |
| Query languages |
5 (SQL, Cypher, Gremlin, GraphQL, MQL) |
2 (Gremlin, REST API) |
| Cypher support |
Yes |
No |
| SQL support |
Yes |
No |
| Data models |
6 |
1 (Graph) |
| Vector search |
Built-in |
No |
| MCP server |
Built-in |
No |
| Weighted SSSP |
Yes |
No |
| Deployment |
Single binary |
Multiple components |
The Comparison at a Glance
| |
ArcadeDB |
ArangoDB |
KuzuDB / LadybugDB |
Memgraph |
FalkorDB |
HugeGraph |
| License |
Apache 2.0 |
BSL 1.1 |
MIT (archived) |
BSL 1.1 |
Source-available |
Apache 2.0 |
| OSI open-source |
Yes |
No |
Yes (but abandoned) |
No |
No |
Yes |
| Data models |
6 |
3 |
1 |
1 |
1 |
1 |
| Query languages |
5 |
1 (proprietary) |
1 |
1 |
1 |
2 (Gremlin, REST) |
| Cypher support |
Yes |
No |
Yes |
Yes |
Yes |
No |
| SQL support |
Yes |
No |
No |
No |
No |
No |
| Gremlin support |
Yes |
No |
No |
No |
No |
Yes |
| Persistence |
Native disk |
Native disk |
Native disk |
In-memory |
Disk (Redis-based) |
Disk (pluggable) |
| Vector search |
Built-in |
Enterprise only |
No |
No |
Built-in (HNSW) |
No |
| MCP server |
Built-in |
No |
No |
No |
No |
No |
| Data size limit |
None |
100GB (Community) |
None |
RAM-bound |
RAM-bound |
None |
| Commercial cost |
$0 |
Enterprise pricing |
N/A |
~$25K/year |
Enterprise pricing |
$0 |
| Active development |
Yes |
Yes |
No (archived) |
Yes |
Yes |
Yes |
Why Licensing Matters More Than You Think
In 2024-2025, we watched multiple databases change their licenses after years of building communities on open-source promises:
- MongoDB moved from AGPL to SSPL in 2018
- Redis moved from BSD to dual-license (RSALv2 + SSPL) in 2024
- ArangoDB moved from Apache 2.0 to BSL 1.1 in 2024
- Elasticsearch moved from Apache 2.0 to SSPL in 2021
Every one of these changes was presented as “necessary for sustainability.” Every one of them restricted what users could do with software they’d invested in.
When you choose a database, you’re not just choosing today’s features — you’re betting on tomorrow’s licensing terms. A database under Apache 2.0 can never pull the rug out from under you. A database under BSL can change the conversion terms, extend the restriction period, or tighten the usage limitations at any time.
ArcadeDB is Apache 2.0 today, and we’ve made a public, permanent commitment to keep it that way. That’s not a marketing claim — it’s a structural guarantee.
So Which One Should You Choose?
Choose ArcadeDB if you want a multi-model database that handles graphs, documents, key-value, time-series, and vector data in one engine — with genuine open-source licensing, no data caps, and built-in AI/MCP integration.
Choose ArangoDB if you’re already invested in AQL and your dataset is under 100GB — but have a migration plan ready for when you hit that ceiling or the license terms change again.
Choose KuzuDB/LadybugDB if you need an embedded analytical graph engine for batch processing and you’re comfortable maintaining a dependency on an archived/forked project.
Choose Memgraph if you need the absolute lowest latency for in-memory real-time graph queries, your dataset fits in RAM, and you have the budget for commercial licensing.
Choose FalkorDB if you’re building AI/GraphRAG applications and want tight integration with LLM workflows, and the source-available license works for your deployment model.
Choose HugeGraph if you need an Apache-licensed graph database with pluggable storage backends for very large-scale deployments, your team is comfortable with Gremlin, and you don’t need Cypher compatibility or weighted shortest-path algorithms.
Key Takeaways
- ArcadeDB is the only Neo4j alternative that combines six data models, five query languages, and a genuine Apache 2.0 license with no data caps or commercial restrictions.
- ArangoDB changed its license from Apache 2.0 to BSL 1.1 in 2024 and capped its free tier at 100GB — a significant shift for existing users.
- KuzuDB was acquired by Apple and archived in October 2025. Community forks exist but carry abandonment risk.
- Memgraph offers fast in-memory graph queries but uses BSL 1.1 (not open source), costs ~$25,000/year commercially, and has documented stability issues.
- FalkorDB brings innovative GraphBLAS architecture, HNSW vector search, and strong GraphRAG positioning, but uses a source-available license and lacks multi-model support beyond graph + vectors.
- HugeGraph is an Apache-licensed project with pluggable storage backends and a separate Vermeer OLAP engine, but trails ArcadeDB Docker by 5-30x on graph algorithm performance (apples-to-apples Docker comparison), lacks Cypher support, and requires a complex multi-component deployment.
- In 2026, only ArcadeDB, HugeGraph, and the archived KuzuDB/LadybugDB use OSI-approved open-source licenses among production graph databases.
Frequently Asked Questions
What is the best open-source alternative to Neo4j?
ArcadeDB is the most versatile open-source Neo4j alternative in 2026. It supports Cypher, SQL, Gremlin, GraphQL, and MQL under a permissive Apache 2.0 license — with no data caps, no commercial restrictions, and six data models in a single engine.
Is ArcadeDB compatible with Neo4j Cypher queries?
Yes. ArcadeDB includes a native OpenCypher engine that passes 97.8% of the official Cypher Technology Compatibility Kit (TCK). Most Cypher queries run as-is without rewriting. ArcadeDB also supports the BOLT protocol for Neo4j driver compatibility.
What happened to KuzuDB?
KuzuDB was acquired by Apple in October 2025, and its GitHub repository was archived. Active development stopped. Community forks like LadybugDB exist but lack corporate backing or guaranteed longevity.
Which graph databases are truly open source in 2026?
ArcadeDB (Apache 2.0), HugeGraph (Apache 2.0), and the archived KuzuDB/LadybugDB (MIT) are the only graph databases using OSI-approved open-source licenses. Memgraph and ArangoDB use Business Source License (BSL 1.1), while FalkorDB uses a source-available license. None of those are considered open source by the Open Source Initiative.
How do I migrate from Neo4j to ArcadeDB?
ArcadeDB provides a built-in Neo4j importer that reads Neo4j export files directly. Export your Neo4j database, run the importer, and your Cypher queries work as-is. See the full migration documentation.
What is the best graph database for AI and LLM agents in 2026?
ArcadeDB is the best graph database for AI integration in 2026. It includes a built-in MCP (Model Context Protocol) server for direct LLM-to-database communication and native vector search for embeddings — all under Apache 2.0 with no plugins or enterprise paywalls required.
Is Memgraph really open source?
No. Memgraph uses the Business Source License 1.1 (BSL), which restricts commercial use. The Open Source Initiative does not recognize BSL as an open-source license. Despite Memgraph’s marketing, neither its Community nor Enterprise edition qualifies as free and open-source software (FOSS). Independent analysis confirms this.
Getting Started with ArcadeDB
Ready to try the most versatile Neo4j alternative?
Docker (fastest way):
docker run --rm -it -p 2480:2480 -p 2424:2424 \
-e JAVA_OPTS="-Darcadedb.server.rootPassword=playwithdata" \
arcdata/arcadedb:latest
Then open http://localhost:2480 and start querying with SQL, Cypher, Gremlin, or GraphQL.
Have questions about migrating from Neo4j? Join our Discord — we’re happy to help.
Last updated: March 2026. This graph database comparison is reviewed and updated regularly to reflect licensing changes, new releases, and market developments.
]]>