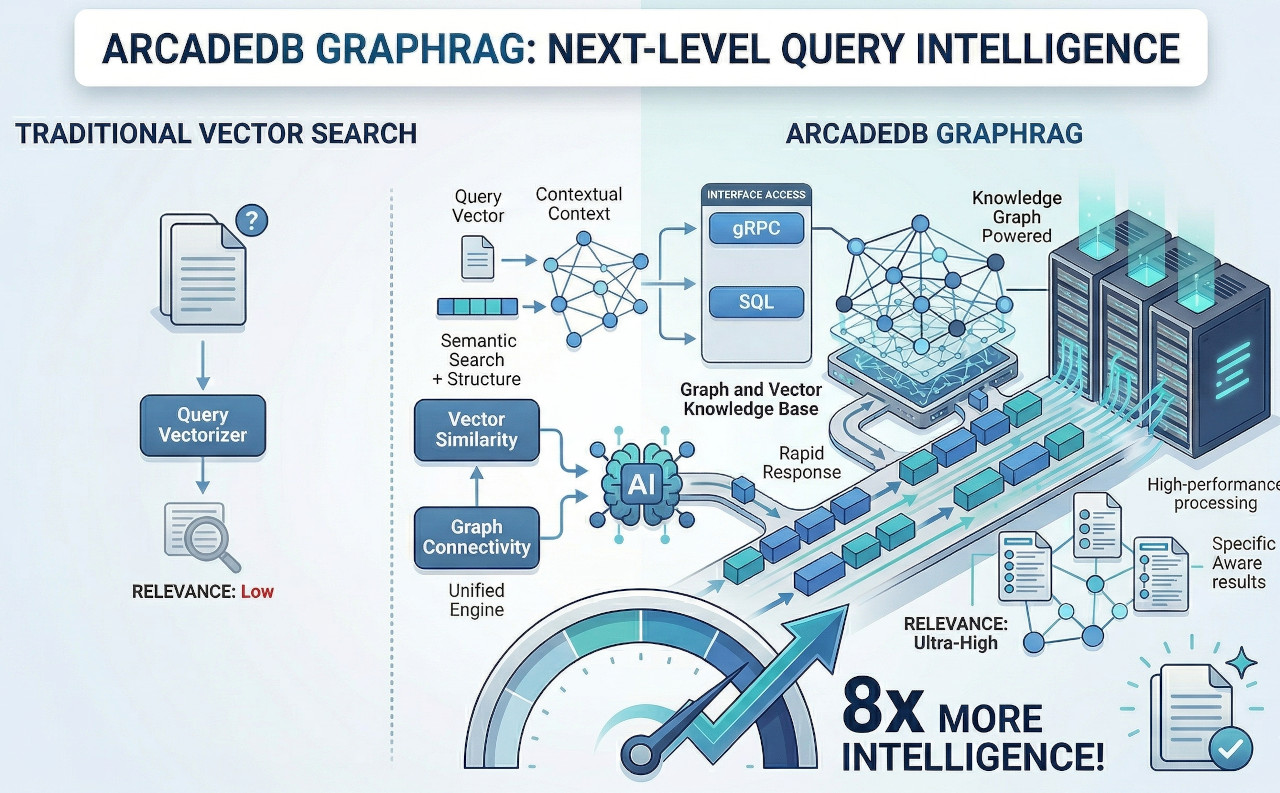
Vector-Only RAG Is Hitting a Wall
Retrieval Augmented Generation transformed how LLMs access knowledge. But the first generation of RAG — chunk documents, embed them, retrieve by cosine similarity — has fundamental limitations. When you treat documents as isolated vectors, you lose the structure: the relationships between entities, the hierarchy of concepts, the temporal evolution of facts.
The result: hallucinations, incomplete answers, and an inability to reason across connected information. Ask a vector-only system "Which researchers at Stanford published papers on the technique used by the company that acquired our competitor?" and it falls apart — that's a 4-hop graph traversal, not a similarity search.
Research consistently shows 20-35% improvement in retrieval precision and up to 65% reduction in hallucinations when knowledge graph context supplements vector similarity. Cedars-Sinai's ESCARGOT system achieved 94.2% accuracy on multi-hop medical reasoning versus 49.9% with standard RAG — nearly doubling performance by adding graph structure.
The industry has a name for this: Graph RAG. But most implementations require stitching together 3-5 separate databases plus ETL pipelines. ArcadeDB handles the entire pipeline in a single engine.
Where Vector-Only RAG Falls Short
Can't traverse entity connections between documents
Unable to perform multi-hop reasoning through entity networks
Treats all text as isolated vectors without semantic organization
Can't answer "what changed since last quarter?"
Separate vector DB + graph DB + search engine + sync pipelines
ETL delays mean the LLM reasons over outdated data